Rust is a hugely popular compiled programming language and accelerating it was an important goal for Firebuild for some time.
Firebuild‘s v0.8.0 release finally added Rust support in addition to numerous other improvements including support for Doxygen, Intel’s Fortran compiler and restored javac and javadoc acceleration.
Firebuild’s Rust + Cargo support
Firebuild treats programs as black boxes intercepting C standard library calls and system calls. It shortcuts the program invocations that predictably generate the same outputs because the program itself is known to be deterministic and all inputs are known in advance. Rust’s compiler, rustc is deterministic in itself and simple rustc invocations were already accelerated, but parallel builds driven by Cargo needed a few enhancements in Firebuild.
Cargo’s jobserver
Cargo uses the Rust variant of the GNU Make’s jobserver to control the parallelism in a build. The jobserver creates a file descriptor from which descendant processes can read tokens and are allowed to run one extra thread or parallel process per token received. After the extra threads or processes are finished the tokens must be returned by writing to the other file descriptor the jobserver created. The jobserver’s file descriptors are shared with the descendant processes via environment variables:
# rustc's environment variables
...
CARGO_MAKEFLAGS="-j --jobserver-fds=4,5 --jobserver-auth=4,5"
...Since getting tokens from the jobserver involves reading them as nondeterministic bytes from an inherited file descriptor this is clearly an operation that would depend on input not known in advance. Firebuild needs to make an exception and ignore jobserver usage related reads and writes since they are not meant to change the build results. However, there are programs not caring at all about jobservers and their file descriptors. They happily close the inherited file descriptors and open new ones with the same id, to use them for entirely different purposes. One such program is the widely used ./configure script, thus the case is far from being theoretical.
To stay on the safe side firebuild ignores jobserver fd usage only in programs which are known to use the jobserver properly. The list of the programs is now configurable in /etc/firebuild.conf and since rustc is on the list by default parallel Rust builds are accelerated out of the box!
Writable dependency dir
The other issue that prevented highly accelerated Rust builds was rustc‘s -L dependency=<dir> parameter. This directory is populated in a not fully deterministic order in parallel builds. Firebuild on the other hand hashes directory listings of open()-ed directories treating them as inputs assuming that the directory content will influence the intercepted programs’ outputs. As rustc programs started in parallel scanned the dependency directory in different states depending on what other Rust compilations finished already Firebuild had to store the full directory content as an input for each rustc cache entry resulting low hit rate when rustc was started again with otherwise identical inputs.
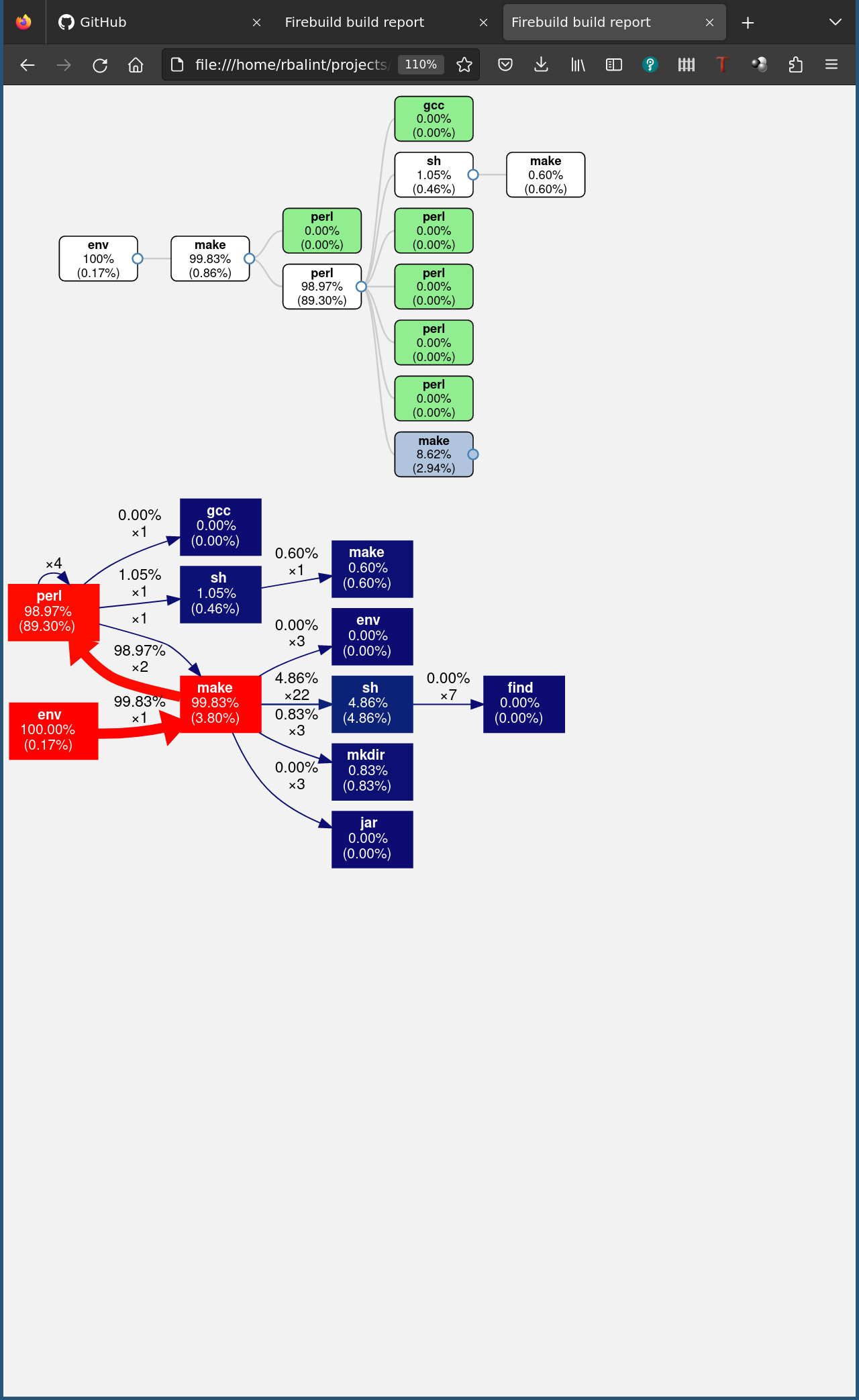
The solution here is ignoring rustc scanning the dependency directory, because the dependencies actually used are still treated as input and are checked when shortcutting rustc. With that implemented in firebuild, too, librsvg’s build that uses Rust and Cargo can be accelerated by more than 90%, even on a system having 12 cores/24 threads!:

On the way to accelerate anything
Firebuild’s latest release incorporated more than 100 changes just from the last two months. They unlocked acceleration of Rust builds with Cargo, fixed Firebuild to work with the latest Java update that slightly changed its behavior, started accelerating Intel’s Fortran compiler in addition to accelerating gfortran that was already supported and included many smaller changes improving the acceleration of other compilers and tools. If your favorite toolchain is not mentioned, there is still a good chance that it is already supported. Give Firebuild a try and tell us about your experience!
Update 1: Comparison to sccache came up in the reddit topic about Firebuild’s Rust acceleration , thus by popular demand this is how sccache performs on the same project:

All builds took place on the same Ryzen 5900X system with 12 cores / 24 threads in LXC containers limited to using 1-12 virtual CPUs. A warm-up build took place before the vanilla (without any instrumentation) build to download and compile the dependency crates to measure only the project’s build time. A git clean command cleared all the build artifacts from the project directory before each build and ./autogen.sh was run to measure only clean rebuilds (without autotools). See test configuration in the Firebuild performance test repository for more details and easy reproduction.
Firebuild had lower overhead than sccache (2.83% vs. 6.10% on 1 CPU and 7.71% vs. 22.05% on 12 CPUs) and made the accelerated build finish much faster (2.26% vs. 19.41% of vanilla build’s time on 1 CPU and 7.5% vs. 27.4% of vanilla build’s time on 12 CPUs).